
Version7.0 Bookページの仕掛け
全体構造
半ば自分の覚書として作ったものです。
大きく分けて2つの系列があります。
上部が狙いでしたが、一部のブラウザーでは動かない事が判ったので、やむを得ず下部を追加しました。
上部構造
Javascript(Jquery)を使いXMLをXSLで動的にHTMLに変換し出力しています。DOM(Document Object Model)という手法です。
各ファイルの役割や動きは図内で説明しているので割愛します。
こういう手法を取った理由は、元データは一つしかなく(booklist.xml)、それさえ更新すれば同じ書評を表示する複数のファイルが全て自動更新できるからです。
JavascriptとXSLファイルが二つずつありますが、中身の90%は共通です。Keyword検索機能を後付けしたのでこんな風になってしまいましたが、最初から考えて上手くやれば共通化できたかもしれません。
元データはMs-Accessに入力し、AccessのExport機能を使いXMLファイルとして出力します。新しい作家さんが追加された時には、同時に日本人/海外の作家リスト(xml)も更新します。これは各ページの選択リストボックスに作家名を表示するためです。
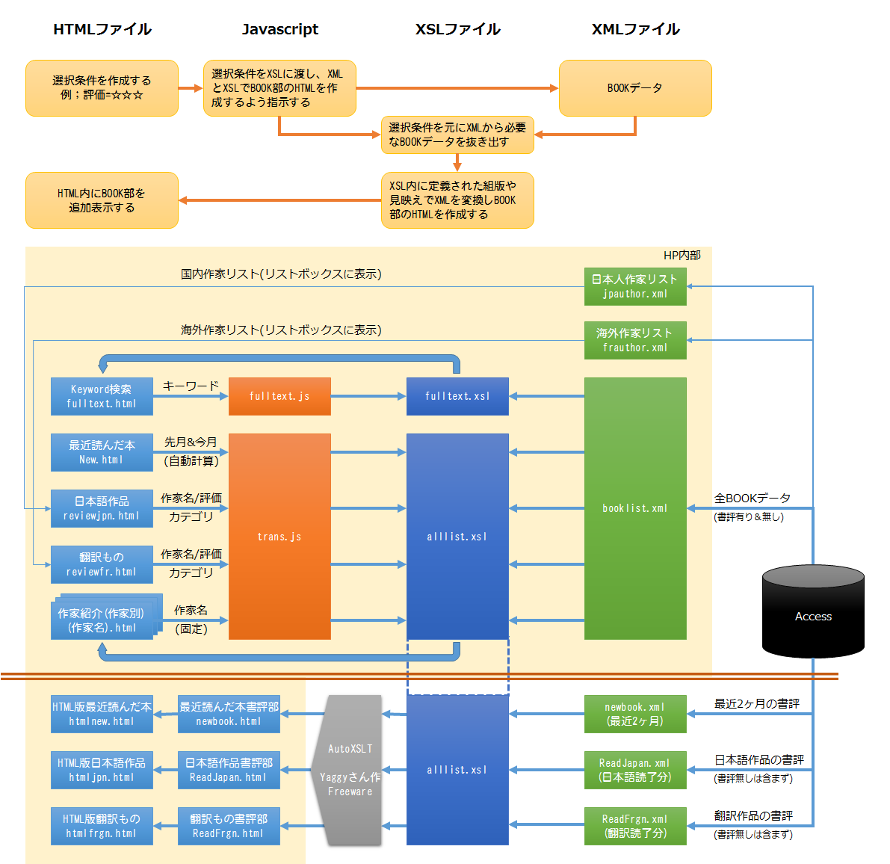
下部構造
MS-Edgeや古いSafari等ではJavascriptでXML/XSLファイルが上手く扱えませんでした。そこで仕方なく作ったのが下部構造です。
MS-Access上に作った3つのクエリ(この場合、条件で絞り込んだ書評データ)をXMLファイルとして出力します。次にYaggyさんという方が作られたFreeware"Autoxslt"を使ってHTMLに変換すると書評部のみのHTMLファイル(例;newbook.html)ができます。これを操作メニューなどの記述したHTML(例;htmlnewk.html)の中に読み込んで完成させます。
ちなみに更新しているのは前のHTML(例;newbook.html)だけで、後ろのHTML(例;htmlnewk.html)は不変です。
構成ファイルの解説
XMLファイル (eXtensible Markup Language)
booklist.xmlの実データ。(
開くのに時間がかかるかもしれません)
XMLは意味を持たせたタグ(<>)で入子状に囲まれた言語です。タグは自分で定義します。例えば私はこのXMLに中で<book>から</book>に囲んだ情報が一冊の本を示し、その中の例えば<title>から</title>に挟まれた部分が書名と定義しています。
XSLファイル (eXtensible Stylesheet Language)
alllist.xslの実データ。
XSLはXML用のスタイルシートです。見てもなかなか理解し辛いと思いますが、例えば
<div id="title">
<h2>
<xsl:value-of select="title"/>
<xsl:value-of select="author"/>
(著)
</h2>
</div>
この中の xsl:value-of select="title"/ は、XML上のtitleを取って来いという指示で、これがHTML化されると
<div id="title">
<h2>
株式会社ネバーラ北関東支社
瀧羽 麻子
(著)
</h2>
</div>
になります。後はこうして出来たHTMLをさらにHLML用のCSSで整形して表示しています。
DOMを含むHTML (Document Object Model)
trans.jsの実データ。
Java ScriptとJqueryで書いた100行にも満たない小さなプログラムです
実際私にはこのようなプログラムを一から書く力はありません。net上でサンプルコードを探し、それを自分のニーズに合わせて部分修正して行く方法で作ったものです。